Abstract
The twentieth century was marked by the publication of a plethora of books on new methods and approaches to teaching English as a second or foreign language, few of which were based on empirically tested claims (Richards & Rodgers, 2001). Pronunciation instruction is perhaps the area of ELT that is most lacking in empirical studies to support its practices, with calls for research to investigate its effects and efficacy constantly made by ELT and second language acquisition specialists (Derwing & Munro, 2005). The recent resurgence in the interest for pronunciation has led to a small increase in the number of experimental studies being conducted on the subject. However, research is still limited to how teaching pronunciation affects learners’ spoken production, with few studies focusing on the potential benefits explicit pronunciation instruction may have on students’ listening comprehension skills. The study described here aimed to investigate whether teaching pronunciation has any spillover effects on learners’ listening skills. The findings presented here imply that teacher training may need to rethink its current approach to the teaching of pronunciation if it is to accommodate for empirically tested evidence.
Literature review
Current practice
Most ELT professionals and institutions in the current communicative approaches and post-methods era have distanced themselves a great deal from the practices associated with audiolingualism. However, when it comes to the teaching of pronunciation, they tend to fall back on listen and repeat, a relic from the audio- lingual years (Sweeting, 2015). Despite the fact that it is easy to administer for teachers, listen and repeat often gives disappointing results and is based on the questionable assumption that speech sounds can be learned by imitation (Messum, 2012). This reliance on imitation may be the result of a combination of a widespread lack of knowledge of the benefits of the explicit teaching of pronunciation and its effects on learners’ listening skills and insufficient or ineffective pronunciation teaching strategies taught to new and experienced teachers in training courses (Kanellou, 2011).
Successful understanding of natural speech entails a combination of top-down and bottom-up processing (Buck, 1995; Rost, 2002). However, since its inception, communicative language teaching has made teachers concentrate on and favour top-down listening skills practices and procedures which improve the learner’s ability to guess what they are hearing. The rationale for these practices is that there is frequently sufficient contextual information to help listeners to infer what is being said, provided they are able to identify parts of the incoming speech they are trying to process (Brown, 1990).
Aural perception
The listening comprehension of spoken language comprises three overlapping phases: perception, parsing, and utilization (Anderson, 2010). Relating words listeners know to the sounds they hear is the first of the three stages proposed. Parsing refers to words being analyzed in units according to grammatical or lexical cues. During utilization, phonological, grammatical, and lexical information in the incoming speech are matched to the listener’s prior knowledge to interpret the meaning and functions of utterances.
The Cohort model of auditory word recognition (Davis, 2007) helps to explain how oral input is processed in the brain. It argues that speech comprehension takes place by continuously processing incoming spoken text as it is heard. At all times, the system processes the best interpretation of presently available input, matching information in the speech signal to prior lexical and grammatical context.
Identification is achieved by comparing incoming speech with known lexical items. Google’s autocomplete search feature serves as an analogy of how this works. As we type letters into the search box, Google’s algorithm predicts and displays search queries based on frequent search activities, linking these results to previous searches and content viewed by users. Much like Google’s autocomplete function, the brain instantly analyses, discards, and matches incoming speech, or queries, according to visual, contextual, grammatical, lexical, and acoustic signals (Silva Neto, 2016).
The Cohort model implies that a learner’s own mispronunciation can potentially act as a barrier to impede listening comprehension. This potential breakdown in communication can be explained in view of the auditory feedback loop (Reed & Michaud, 2011), which suggests that clearer production, i.e. pronunciation on the part of the speaker, helps to facilitate their own perception. The model proposed in the feedback loop posits that speakers use their own output – their own pronunciation and acoustic representation of a sound— as input for their reception and perception. Therefore, learners’ increasingly target-like pronunciation may ease and reinforce their perception during listening comprehension tasks and spontaneous unscripted conversations.
The acoustic representation of a concept is what de Saussure called the signifier (Bibeau, 1983), which would generate a concept, the signified, in the minds of interlocutors upon successful identification of the received acoustic signal; this matching cycle, or speech circuit proposed by de Saussure, includes simultaneous production and reception phases on the part of speakers and hearers. The production phase consists of three sub-stages as follows:
Speaker
- A concept evokes a linguistic acoustic image in the brain, a psychological process.
- The brain transmits an impulse corresponding to the image to the articulators, i.e. the entire vocal tract, a physiological process.
- Sound waves produced by articulators travel from the speaker’s mouth to the ears of listeners, a physical process.
The receptive phase is subdivided into the following stages:
Hearer
- An incoming speech signal is picked up by the ear, a physical process.
- Air vibrations physically act on the parts of the inner ear so as to produce activations of the sensory nerves, which then arrive at the brain and create a perceptual sensation, a physiological process.
- The sound image evokes its associated concept, a psychological process.
Neuroscience
De Saussure’s speech circuit anticipated modern neurology in establishing a close link between perception and the motor cortex (Kemmer, 2009), the area of the brain responsible for planning, controlling, and executing voluntary movements. The role of the motor cortex is clearly identified when activity during speech perception is localized in regions of the ventral sensorimotor cortex. This is the area of the brain involved in highly coordinated movements of human speech production (Cheung et al., 2016). The Ventral sensorimotor reflects phonological information during speech perception and exerts a causal influence on language understanding (Schomers & Pulvermüller, 2016). Specific motor circuits that reflect distinctive phonetic features of speech sounds picked up by the hearer’s ear are engaged during speech perception experiments. The results of these experiments provide direct neuroimaging support for links between phonological mechanisms for speech perception and production (Pulvermüller et al., 2006).
Teacher training
Speech production and pronunciation, its external representation, are primarily a physical and muscular activity. Therefore, conscious attention must be paid to work on the muscles and articulatory systems involved in producing target sounds both on segmental and suprasegmental levels (Underhill, 2013). Explicit phonetics instruction on the prosodic features of language such as suprasegmental practice, as well as stress, rhythm, intonation, and features of connected speech, has demonstrated beneficial results in learners’ production (Gordon et al., 2012). In addition, explicit pronunciation instruction has also demonstrated improvements in students’ listening comprehension in language tests (Ahangari et al., 2015; Khaghaninejad & Maleki, 2015; Levis, 1999; Lord, 2005).
However, although pronunciation instruction is considered important by teachers and researchers alike, it is often relegated to the sidelines of the ESL/EFL curriculum and at times completely ignored altogether (Derwing, 2009). Target language input alone is not sufficient to create changes in learners’ performance across the four language skills (Flege & Hillenbrand, 1984; Strange, 1995). Learners may need to receive appropriate pronunciation instruction if they are to make progress in the intelligibility of their speech in ways that can positively aid their own listening skills (Khaghaninejad & Maleki, 2015). However, teacher training does not currently provide teachers with a sufficient basis to work from (Fraser, 2000), with additional training needed to develop teachers’ ability to embed pronunciation practices in an established curriculum (Darcy et al., 2012).
The current study
The literature review suggests that improved pronunciation can lead to enhanced perception, i.e. listening skills by learners of a language. The present study attempts to observe such assumptions by analyzing the effects of explicit instruction of pronunciation on learners’ listening skills. To this end, the following research question was investigated: To what extent does the explicit teaching of pronunciation have an effect on learners’ scores in the listening component of an internationally recognized English proficiency test?
Participants
The participants were a group of 21 Brazilian students working towards the Common European Framework of Reference (CEFR) A2 level. Their ages ranged between 16 and 54 (M = 28.8; SD = 10.66); there were 10 females and 11 males. All participants were volunteers who had had 100-150 hours of general English lessons over three terms of 50 hours of instruction within an 18-month period. The general English course participants were enrolled in offered two 100-minute lessons a week. The participants’ history of English language learning was taken before the study began to ensure none of the volunteers had studied English prior to their entry in the general English course. Participants were then split into two different groups. The treatment group was comprised of 11 students and the control group 10.
Procedures
The study followed a pretest-posttest quasi-experimental design. All participants sat a randomly selected Key English Test (KET) listening component from Cambridge English Language Assessment. The KET exam is part of Cambridge’s exam suite and is at CEFR’s A2 level. The test consists of 25 multiple-choice listening comprehension questions. After the first data collection phase, volunteers were ready to start their programme.
The treatment group was given six pronunciation lessons of 60 minutes over a period of six weeks in addition to their regular general English course. Meanwhile, the control group had their regular general English lessons over the same period of time, i.e., treatment as usual.
Instruction
The pronunciation lessons were designed based on a combination of activities suggested in Sound Foundations (Underhill, 2005) and Teaching Pronunciation, a course book and reference guide (Celce-Murcia et al., 2010). As all participants were Brazilian speakers of Portuguese, Learner English (Swan & Smith, 2001) was used to make sure the specific difficulties faced by Brazilians were addressed.
The six weeks of treatment were divided into three focus blocks. The first block had a focus on individual sounds and segmental work, with special attention being paid to the sounds which do not occur in Brazilian Portuguese, and therefore tend to present a bigger challenge for learners. For the second focus block, the treatment consisted of work on suprasegmental practice and aspects of connected speech, such as assimilation, elision, vowel reduction, strong and weak forms, and liaison.
The final two weeks were dedicated to work on intonation, stress, and rhythm.
All the lessons had a presentation–practice–production design. Instruction aimed to explicitly present volunteers with rules about pronunciation. In the segmental phase of the programme, students worked with articulatory diagrams, videos, and animations that demonstrate how individual sounds are produced. Volunteers made use of The Sounds of Speech, a web-based tool for the presentation and practice of individual sounds created by the University of Iowa (see Figure 1). A series of videos by the BBC Learning English website on how individual sounds are produced was also used during this phase (see Figure 2). Sounds: Pronunciation App by Macmillan Education was introduced in lessons to cater for students who felt they needed more individual practice on segmental features (see Figure 3). Connected speech, intonation, rhythm, and stress were dealt with using rules prescribed in Sound Foundations and Teaching Pronunciation, a course book and reference guide.
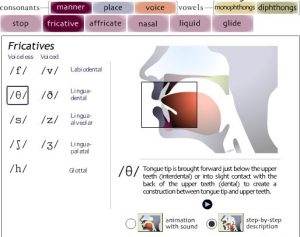
Figure 1. Interactive sagittal section animation demonstrating manner of articulation of /θ/.
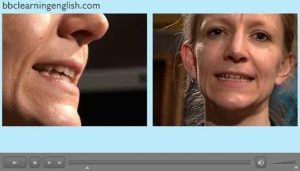
Figure 2. Still image of BBC video showing how the sound /iː/ is produced.
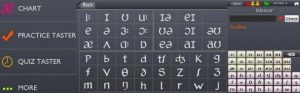
Figure 3. Different practices available on Sounds: The Pronunciation App.
Upon completion of the pronunciation programme, both the treatment and the control group sat another randomly selected Cambridge KET listening test in order to have their results analyzed and compared.
Results
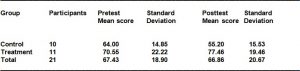
Table 1. Descriptive statistics on the pretest and posttest for both groups.
Table 1 shows that the means for the control group were 64 and 55.2 on the pretest and posttest respectively, while the treatment group scored 70.55 on the pretest and 77.46 on the posttest. Surprisingly, the mean for the control group on the posttest was lower than on the pretest. This may have been the result of a comparably more difficult KET test. An independent-samples t-test was conducted to establish whether the difference between the scores of the groups in the pretest was significant. A significant result would indicate that the groups were at different levels of ability. There was no significant difference in scores for the control group (M = 64, SD = 14.85) and the treatment group (M = 70.55, SD = 22.20) conditions; t (19) = -0.79, p=.44. This result indicates that both groups were at comparable levels of ability prior to treatment.
In order to answer the research question posed in this study, a two-way repeated measures ANOVA with treatment as an independent variable and the percentage of correct answers on the pre-test and post-test as dependent variables was performed to investigate whether the interaction between time and group was statistically significant. The interaction effect was significant, F (1, 19) = 6.15, p = .02, η2 = 2.44). The analysis demonstrates that the treatment group showed a statistically and significantly greater score on the pre-test versus the post-test than the control group did.
Discussion and Conclusions
The current study investigated the effects of explicit teaching of pronunciation on the performance of learners in the listening component of an internationally recognized proficiency exam, the Cambridge KET. The results of the data analysis revealed a significant effect of instruction on the treatment group, which was given instruction on segmental, suprasegmental, and prosodic features of pronunciation, when compared to the control group. Such findings support research which has shown that explicit phonetics instruction is beneficial for learners.
Moreover, the significant difference in performance between the control and treatment groups supports the view that mere input of target language does not provide sufficient conditions to create meaningful changes in students’ performance across language skills and systems. Furthermore, the findings presented here underscore that explicit phonetic instruction seemingly enhances learners’ overall performance on listening tasks, which is in line with results of previous studies (Ahangari et al.,2015; Gordon et al., 2012; Khaghaninejad & Maleki, 2015; Levis, 1999; Lord, 2005). In addition, the outcomes of this research are in keeping with recent observations from the field of neuroscience, which demonstrate the engagement of speech production areas of the brain during listening activities, indicating a close link between production and perception (Cheung et al., 2016; Pulvermüller et al., 2006; Schomers & Pulvermüller, 2016).
Pronunciation instruction has, for a long time, been the Cinderella of language teaching, being neglected and disconnected from other language learning activities, while lexis and grammar have been dominant in coursebooks, materials, lesson plans, and teacher training (Underhill, 2013). Many teachers remain skeptical about how practical the teaching of pronunciation can be, and in consequence continue to consider explicit pronunciation instruction of relatively little importance in their practice (Barrera Pardo, 2004). ELT has grown accustomed to the pre-while-post listening framework; slowly guiding students to feeling more comfortable with the auditory input, at the same time it tries to shield them from the frustration of not being able to truly decode incoming speech. Pronunciation has come to be considered as of lesser importance in a communicatively orientated classroom as it has traditionally been viewed as a component of linguistic rather than communicative competence or as an aspect of accuracy rather than conversational fluency (Pennington & Richards, 1986, p. 207).
Teacher training also plays an important role in relegating pronunciation to a secondary level, since available training often does not cover the most essential aspects of knowledge about speech and pronunciation, with some trainers’ manuals going as far as stating that trainers should point out to trainees that when teaching they should not rush into pronunciation instruction, given that like other aspects of language learning, it tends to follow its own natural development. This is in direct opposition to Fraser (2000), who suggests that trainee teachers should receive instruction on how to teach pronunciation as part of their TESOL courses and that existing teachers should be able to receive professional development in pronunciation teaching.
Communicative language teaching and the post-methods era have not brought considerable new developments to the teaching of pronunciation, which means listen and repeat is to this day the default practice in most ESL/EFL classrooms around the world. Many teachers and institutions still justify their stance by claiming that imitation is how children learn the speech sounds of their first language, and therefore it makes sense to use the same principle when learning a new language. However, there is mounting evidence that they do not (Messum, 2012).
There are some limitations to the present study. First, the relatively small number of participants, N=21, and the fact that volunteers all come from the same L1 background put restrictions on the extent to which it can be inferred that similar effects will be observed across a larger and more diverse group of learners.
Participants’ oral production was not assessed prior to and upon the completion of the programme, rendering it impossible to conclude beyond anecdotal evidence that explicit pronunciation instruction had an effect on their oral production. Thus, limiting the assumption that improved spoken performance leads to superior listening perception. Further research that addresses these issues is necessary. Despite its shortcomings, the present study demonstrates that explicit pronunciation instruction may be beneficial for learners’ overall performance on listening tests.
Although ELT has, since the appearance of Communicative Language Teaching and the post-methods years, focused on intelligibility, the most important aspect of all communication (Munro, 2011), research in language teaching and neuroscience supports the theory that it is equally important to help students achieve a level of pronunciation accuracy that would also help to foster inter-intelligibility (Neto, 2016), where learners’ speech is understood and serves as a perception model to guarantee their own listening comprehension.
Considering the findings in this and other studies on the effects of pronunciation instruction on learners’ listening skills and the contributions from the field of neuroscience, it stands to reason that a shift in teacher training practices and beliefs about pronunciation and its effects on listening comprehension may thus be needed if ELT is to accommodate for recent empirical evidence.
References
Anderson, J. R. Cognitive psychology and its implications. 7th. ed. New York, NY: Worth Publishers, 2010.
Ahangari, S., Rahbar, S., & Maleki, S. E. (2015). Pronunciation or Listening Enhancement: two birds with one stone. International Journal of Language and Applied Linguistics, 1(2), 13–19.
Barrera Pardo, D. (2004). Can pronunciation be taught? A review of research and implication for teaching. Revista Alicantina de Estudios Ingleses, 17(Nov), 6–38.
Bibeau, G. (1983). Ferdinand de Saussure. Québec Français, 50, 94–95.
Borg, S. (2009). English language teachers’ conceptions of research. Applied Linguistics, 30(3), 358–388.
Brown, G. (1990). Listening to spoken English. London: Longman.
Buck, G. (1995). How to become a good listening teacher. In D. Mendelsohn and J. Rubins (Eds.). A guide for the teaching of second language listening (pp. 113–131). San Diego, CA: Dominie Press.
Celce-Murcia, M., Brinton, M. D., Goofwin, M. J., & Griner, B. (2010). Teaching pronunciation: A course book and reference guide (2nd ed.). Cambridge: Cambridge University Press.
Cheung, C., Hamiton, L. S., Johnson, K., & Chang, E. F. (2016). The auditory representation of speech sounds in human motor cortex. eLife, 5(March 2016), 1–19. https://doi.org/10.7554/eLife.12577
Davis, M. H. (2007). The Cohort Model of Auditory Word Recognition. Word Journal of the International Linguistic Association, 8(5), 1–6.
Darcy, I., Ewert, D., & Lidster, R. (2012). Bringing pronunciation instruction back into the classroom: An ESL teachers’ pronunciation “toolbox”. Proceedings of the 3rd Pronunciation in Second Language Learning and Teaching Conference, 93–108.
Derwing, T. M. (2009). Utopian Goals for Pronunciation Teaching. Proceedings from the 1st Conference of Pronunciation in Second Language Learning and Teaching, 24–37.
https://www.researchgate.net/publication/267951652_Utopian_Goals_for_Pronunciation_Teaching
Derwing, T. M., & Munro, M. J. (2005). Second Language Accent and Pronunciation Teaching: A Research-Based Approach. TESOL QUARTERLY, 39(3), 379–397.
Flege, J. E. & Hillenbrand, J. (1984). Limits on pronunciation accuracy in adult foreign language speech production. Journal of the Acoustical Society of America, 76, 708–721.
Fraser, H. (2000). Coordinating Improvements in Pronunciation Teaching for Adult Learners of English as a Second Language. Retrieved from https://helenfraser.com.au/wp-content/uploads/ANTA-REPORT-FINAL.pdf
Gordon, J., Darcy, I., & Ewert, D. (2012). Pronunciation teaching and learning: Effects of explicit phonetic instruction in the L2 classroom. Proceedings of the 4th Pronunciation in Second Language Learning and Teaching Conference, 194–206.
Kanellou, V. (2011). The place and practice of pronunciation teaching in the context of the EFL classroom in Thessaloniki, Greece. Retrieved from http://orca.cf.ac.uk/28787/
Khaghaninejad, M. S & Maleki, A. (2015). The effect of explicit pronunciation instruction on listening comprehension: Evidence from Iranian English learners. Theory and Practice in Language Studies, 5, (6), 1249–1256.
Kemmer, S. (2009). Guided commentary on de Saussure’s Course in Modern Linguistics. Retrieved from http://www.ruf.rice.edu/~kemmer/Found/saussureessay.html
Levis, J. M. (1999). Intonation in theory and practice, revisited. TESOL Quarterly, 33, 37–63.
Lord, G. (2005). (How) Can we teach foreign language pronunciation? On the effects of a Spanish phonetics course. Hispania, 88, 557–567.
Messum, P. (2012). Teaching pronunciation without using imitation: Why and how. In. J. Levis & K. LeVelle (Eds.). Proceedings of the 3rd Pronunciation in Second Language Learning and Teaching Conference, Sept. 2011. (pp. 154–160). Ames, IA: Iowa State University.
Munro, M. J. (2011). Intelligibility: Buzzword or buzzworthy?. In. J. Levis & K. LeVelle (Eds.). Proceedings of the 2nd Pronunciation in Second Language Learning and Teaching Conference, Sept. 2010. (pp. 7–16), Ames, IA: Iowa State University.
Pennington, M. C. and Richards, J. C. (1986). Pronunciation revisited. TESOL Quarterly, 20(2), 207–225.
Pulvermüller, F., Huss, M., Kherif, F., Moscoso del Prado Martin, F., Hauk, O., & Shtyrov, Y. (2006). Motor cortex maps articulatory features of speech sounds. Proceedings of the National Academy of Sciences of the United States of America, 103(20), 7865–7870.
Reed, M. & Michaud, C. (2011). An integrated approach to pronunciation: Listening comprehension and intelligibility in theory and practice. In. J. Levis & K. LeVelle (Eds.). Proceedings of the 2nd Pronunciation in Second Language Learning and Teaching Conference, Sept. 2010. (pp. 95–104), Ames, IA: Iowa State University.
Richards, J. C. and Rodgers, T. S. (1987). Approaches and methods in language teaching. Approaches and Methods in Language Teaching, 14–30.
Rost, M. (2002). Teaching and researching listening. Harrow, UK: Pearson Education.
Silva Neto, A. F. (2016). Improving listening skills in a foreign language through working on pronunciation. Teacher Trainer Journal, 30(Autumn 2016), 15–17.
Schomers, M. R., & Pulvermüller, F. (2016). Is the Sensorimotor Cortex Relevant for Speech Perception and Understanding? An Integrative Review. Frontiers in Human Neuroscience, 10(September).
Strange, W. (1995). Cross-language studies of speech perception: A historical review. In W. Strange (Ed), Speech Perception and Linguistic Experience: Issues in cross-language research (3–45). Timonium, MD: York Press.
Swan, M., & Smith, B. (Eds.).(2001). Learner English: A teacher’s guide to interference and other problems. Cambridge: Cambridge University Press.
Sweeting, A. (2015). Awakening Sleeping Beauty: Pronunciation instruction beyond ‘listen and repeat’. IATEFL Pronunciation Special Interest Group Newsletter, (52), 1–5.
Underhill, A. (2005). Sound Foundation: Learning and teaching pronunciation. Oxford: Macmillan.
Underhill, A. (2013). Cinderella, integration and the pronunciation turn. IATEFL Pronunciation Special Interest Group Newsletter, (49), 1–5.
Author Bio.
Augusto has been in ELT for over 20 years. He holds a BEd in English and Portuguese languages and Literatures, a Cambridge CELTA, and a certificate in TESOL from Anaheim University. He is currently the Assistant Director for University Guidance & Careers at St. Paul’s, a British School Overseas, in São Paulo, Brazil. His main interests are the teaching of pronunciation and its spillover effects, research into second language speech perception and production, and developing ELT practices that stem from research. He is an international conference speaker, with workshops and talks including TESL Ontario and TESL Saskatchewan conferences. He has also written for IATEFL’s SpeakOut, The Teacher Trainer Journal, and Brazil-TESOL.